AZURE DATA ENGINEERING
NYC 311 Service Requests Lakehouse
Azure-first medallion lakehouse for NYC 311 operational analytics. Proven cloud path from raw API landing to ADLS-backed bronze, silver, and gold datasets in Databricks.

Evidence includes cloud execution screenshots, workflow proof, and ADLS-backed validation. Reporting definitions and dashboard mockup assets are documented as future reporting support.
Quick Scan
Proof at a Glance
A recruiter-facing summary of the cloud path, outputs, and milestone evidence captured in the repo.
Source
NYC 311 REST API
Landing
ADF raw JSON -> ADLS
Processing
Databricks bronze / silver / gold
Outputs
fact table + 3 gold marts
Proof
Milestones 9, 10, 11
Business Context
Operational Analytics Problem
This project is framed around the analytics questions that city-service stakeholders would ask once raw service request events are organized into a durable lakehouse model.
Business Problem
NYC 311 service request data can support operational analytics for city-service demand, agency workload, complaint trends, resolution time, and backlog monitoring. The lakehouse pattern makes it easier to move from raw API extraction into reusable analytics outputs without blurring ingestion, quality, and reporting responsibilities.
Key Questions Answered
- How many requests arrive each day?
- Which agencies and complaint types drive the most demand?
- How long does it take to resolve service requests?
- Where is backlog building up?
Current Scope
Current Proven Path vs Target Architecture
The page separates what is cloud-proven today from the broader architecture the repo is designed to support.
Cloud-Proven
Current Proven Path
Broader Design
Target Architecture
Honest Status
- Current proven cloud path: ADF raw landing + Databricks handoff + ADLS-backed Delta processing.
- Workflow proof: real Databricks job/workflow evidence.
- Power BI: mockup/reporting definitions only, not a fully deployed public dashboard.
- Infra JSON: starter deployment documentation, not full production IaC.
Execution Sequence
Pipeline Execution Flow
The current Milestone 11 operating path starts in ADF, hands off to Databricks, and closes with output validation.
- 1
ADF CopyNYC311ToBronzeRaw calls the NYC 311 API and lands bounded raw JSON to ADLS.
- 2
RunDatabricksBronzeHandoff passes runtime parameters such as environment, run_date, window_start, window_end, batch_id, and raw_landing_path.
- 3
01_ingest_nyc311_raw reads landed raw JSON and writes the bronze Delta table.
- 4
02_bronze_dedup_metadata republishes deduplicated bronze.
- 5
Silver notebooks clean requests, standardize locations/categories, and apply quality rules.
- 6
Gold notebooks build dimensions, fact table, and reporting marts.
- 7
Validation confirms outputs and proves the pipeline execution.
Data Model
Medallion Layers
Bronze preserves source fidelity, silver standardizes and cleans, and gold delivers analytics-ready dimensional outputs.
Bronze
Bronze
Raw landing plus ingestion metadata stays close to source while preserving replay and lineage context.
- Raw NYC 311 JSON
- Ingestion metadata
- Dedup and lineage handling
Silver
Silver
Standardized, quality-checked service request records become reusable for downstream modeling.
- Cleaned service requests
- Standardized locations
- Standardized categories
- Reusable data quality rules
Gold
Gold
Analytics-ready star-schema outputs and marts support reviewer-friendly business questions.
- dim_date, dim_agency, dim_complaint_type, dim_location, dim_status
- fact_service_requests
- mart_request_volume_daily
- mart_service_performance
- mart_backlog_snapshot
Reporting Surface
Analytics-Ready Gold Outputs
These Gold-layer marts translate cleaned service request data into reporting-ready outputs for demand, performance, and backlog analysis.
Request Volume Daily
Daily request volume trends for monitoring demand patterns and reporting period-over-period activity.
Service Performance
Agency and complaint-type level performance output for comparing closure volume and resolution time.
Backlog Snapshot
Open request monitoring by status, agency, and snapshot date to identify backlog risk.
Reporting definitions and dashboard mockup assets are included in the repo to show how these Gold marts support downstream BI analysis.
Execution Evidence
Execution Proof
These screenshots are sourced from the project's milestone evidence folders and demonstrate real cloud pipeline execution.
Milestone 11
4 proof assetsADF Raw Landing + Databricks Handoff
Current proven cloud path lands raw JSON in ADLS, hands off to Databricks, and closes with ADLS-backed Delta validation.
These proof assets show ingestion, storage landing, Databricks handoff, and final validation across the current cloud path.
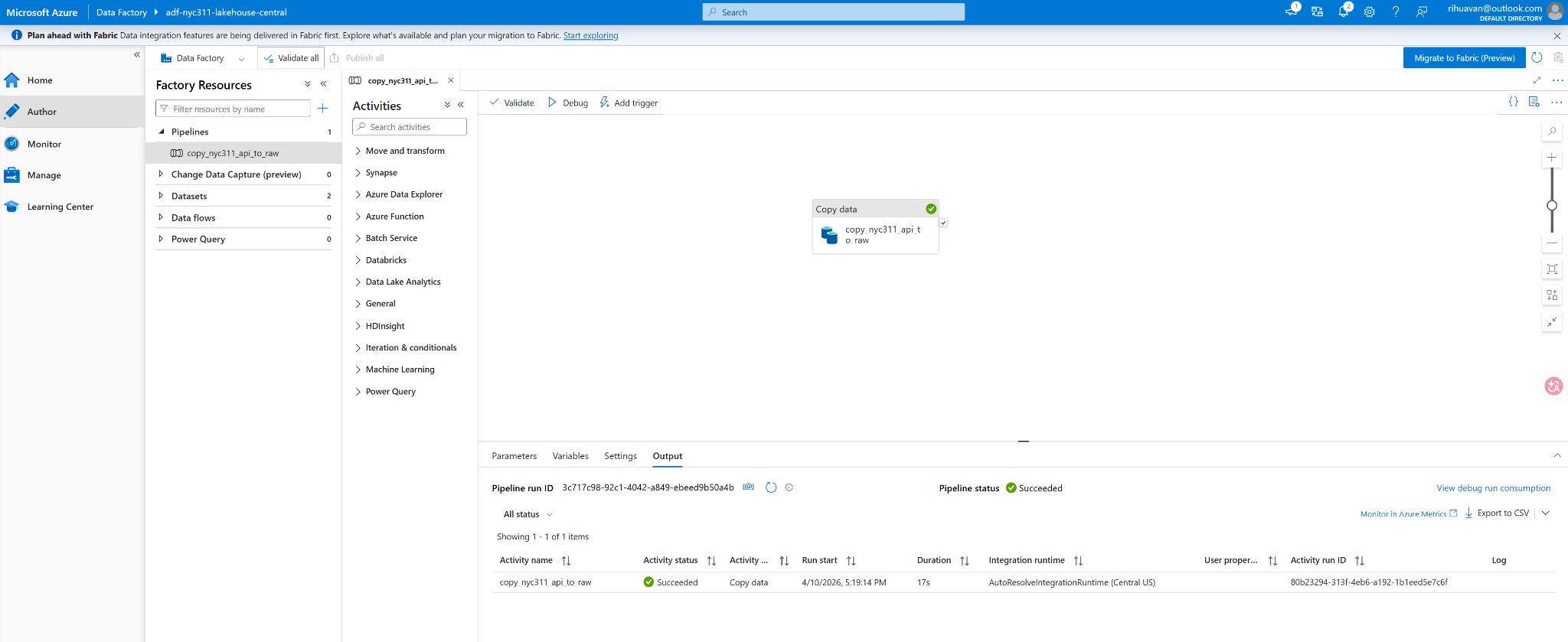
ADF PIPELINE
ADF pipeline run
REST extraction completed successfully in Azure Data Factory.
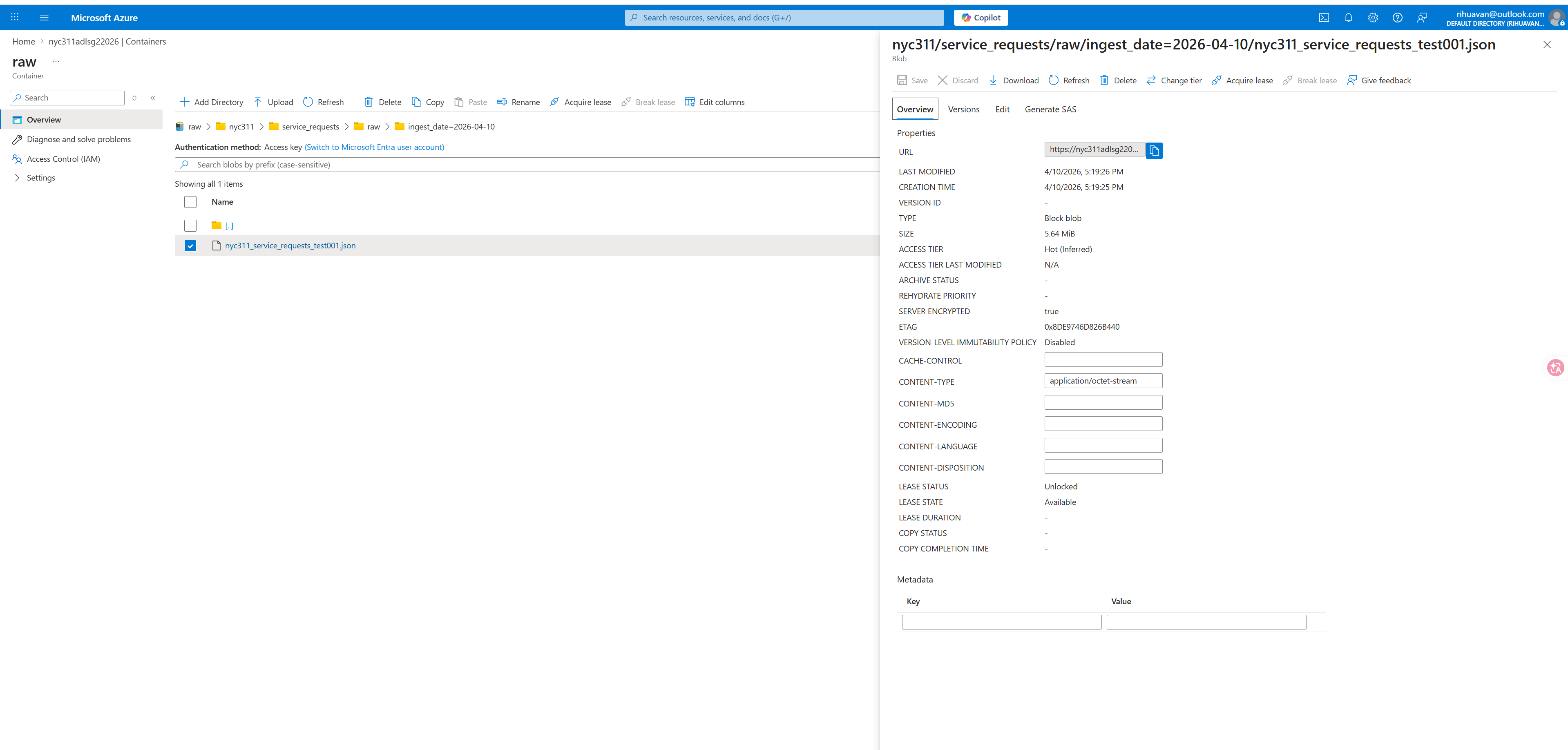
ADLS STORAGE
Raw JSON landed in ADLS
Raw payload landed in ADLS storage.
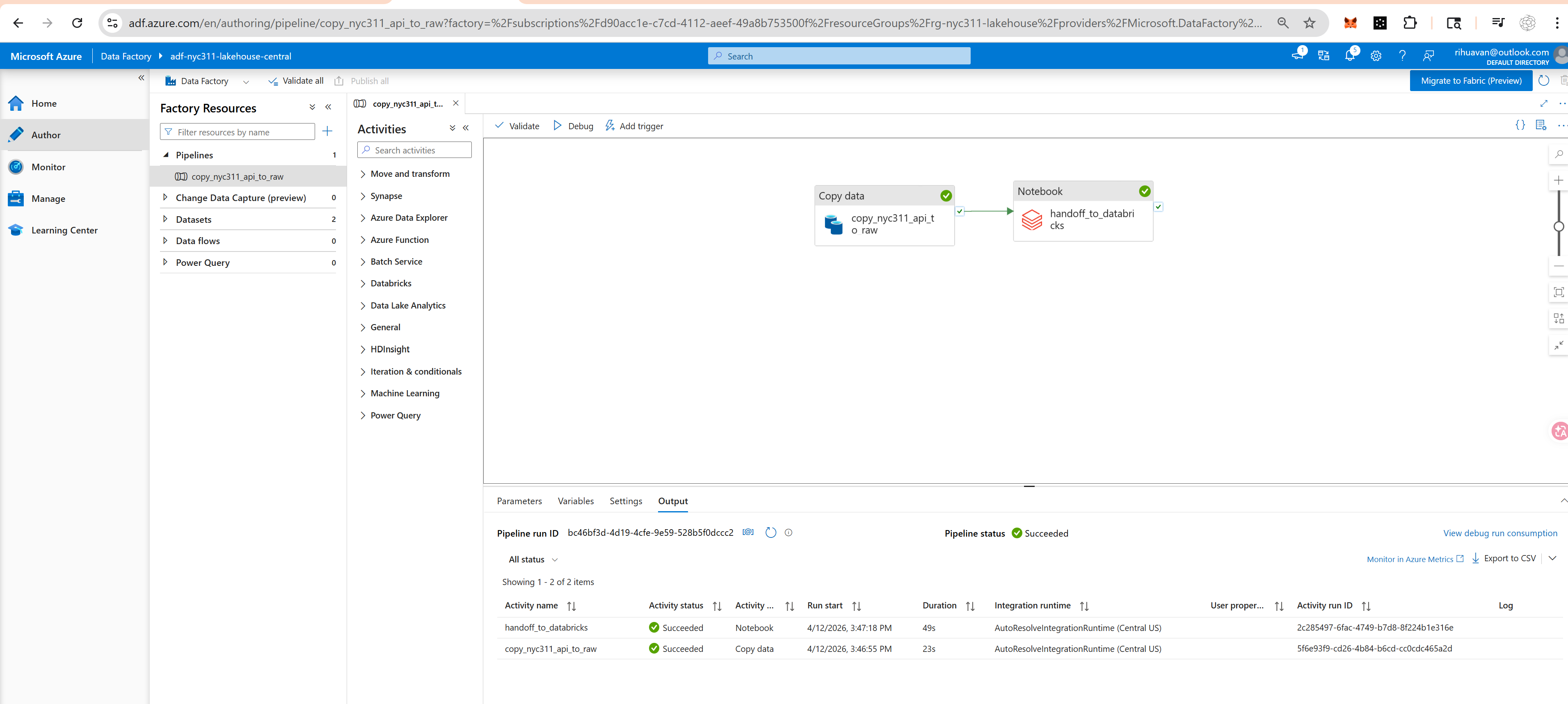
DATABRICKS HANDOFF
Bronze handoff
ADF passed runtime context to Databricks for bronze ingestion.
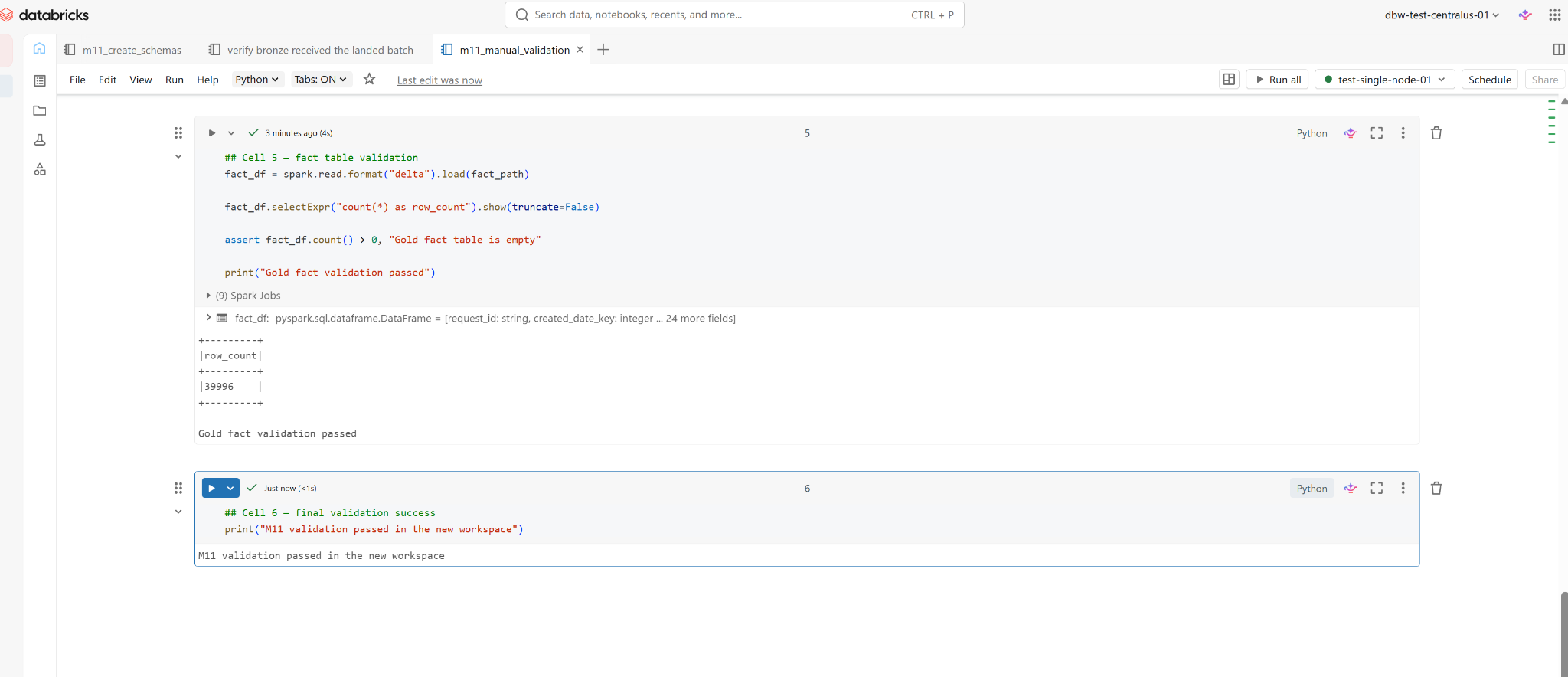
VALIDATION
Final validation
ADLS-backed Delta outputs passed validation.
Implementation Surface
Technical Implementation
The repo is intentionally reviewable: notebook exports, Python modules, SQL assets, docs, and starter deployment contracts are all inspectable.
Python Modules
Ingestion, transformation, data quality, and runtime helpers.
Databricks Notebooks
Setup, bronze, silver, gold, and validation notebook exports.
SQL Assets
DDL, mart definitions, and validation SQL.
Runbooks & Docs
Architecture notes, pipeline runbook, troubleshooting, and evidence docs.
Workflow Definition
Databricks job task chain and workflow structure.
ADF Pipeline Contract
REST-to-ADLS raw landing and handoff parameters.
Design Choices
Engineering Decisions
This project is designed to show credible execution and sound data-engineering judgment without overstating scope.
Why Lakehouse
Raw API data becomes reusable analytics-ready datasets across bronze, silver, and gold without collapsing ingestion, quality, and reporting logic into one layer.
Why Notebook Exports + Python Modules
The repo keeps implementation logic inspectable while still proving cloud notebook execution, which makes review easier for hiring managers and technical peers.
Why Validation Matters
Validation shows outputs were produced and gives reviewers confidence that the pipeline completed beyond diagram-level architecture claims.
What Is Not Overclaimed
Power BI is currently a mockup/reporting layer, and infra JSON is starter deployment documentation rather than complete production IaC.
Recruiter Summary
What This Project Demonstrates
Cloud data pipeline thinking
ADF handoff boundaries, ADLS landing, Databricks processing, and reviewer-readable operating flow.
Medallion modeling and data quality
Bronze, silver, and gold layers with dimensions, facts, marts, and reusable quality controls.
Execution proof, documentation, and reviewer-ready evidence
Runbooks, workflow proof, screenshot folders, and scoped claims about what is implemented today.
This project demonstrates an end-to-end Azure data engineering workflow with real cloud execution proof, analytics-ready outputs, and honest documentation around current scope versus future work.
Next Step
Explore the Project
Use the repo, architecture notes, proof folders, and documentation trail to review the project from design through execution evidence.
Supporting docs include architecture notes, the Milestone 11 runbook, workflow JSON, reporting definitions, and milestone screenshot folders.